HADOOP-PR000007 Online Practice Questions and Answers
You want to perform analysis on a large collection of images. You want to store this data in HDFS and process it with MapReduce but you also want to give your data analysts and data scientists the ability to process the data directly from HDFS with an interpreted high- level programming language like Python. Which format should you use to store this data in HDFS?
A. SequenceFiles
B. Avro
C. JSON
D. HTML
E. XML
F. CSV
Examine the following Hive statements:
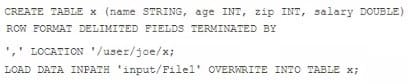
Assuming the statements above execute successfully, which one of the following statements is true?
A. Hive reformats File1 into a structure that Hive can access and moves into to/user/joe/x/
B. The file named File1 is moved to to/user/joe/x/
C. The contents of File1 are parsed as comma-delimited rows and loaded into /user/joe/x/
D. The contents of File1 are parsed as comma-delimited rows and stored in a database
In a large MapReduce job with m mappers and n reducers, how many distinct copy operations will there be in the sort/shuffle phase?
A. mXn (i.e., m multiplied by n)
B. n
C. m
D. m+n (i.e., m plus n)
E. mn (i.e., m to the power of n)
In a MapReduce job with 500 map tasks, how many map task attempts will there be?
A. It depends on the number of reduces in the job.
B. Between 500 and 1000.
C. At most 500.
D. At least 500.
E. Exactly 500.
Consider the following two relations, A and B.
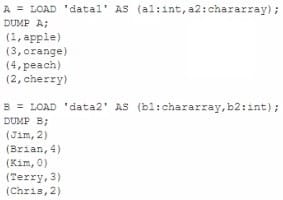
Which Pig statement combines A by its first field and B by its second field?
A. C = DOIN B BY a1, A by b2;
B. C = JOIN A by al, B by b2;
C. C = JOIN A a1, B b2;
D. C = JOIN A SO, B $1;
You need to run the same job many times with minor variations. Rather than hardcoding all job configuration options in your drive code, you've decided to have your Driver subclass org.apache.hadoop.conf.Configured and implement the org.apache.hadoop.util.Tool interface.
Indentify which invocation correctly passes.mapred.job.name with a value of Example to Hadoop?
A. hadoop "mapred.job.name=Example" MyDriver input output
B. hadoop MyDriver mapred.job.name=Example input output
C. hadoop MyDrive 璂 mapred.job.name=Example input output
D. hadoop setproperty mapred.job.name=Example MyDriver input output
E. hadoop setproperty ("mapred.job.name=Example") MyDriver input output
In Hadoop 2.0, which TWO of the following processes work together to provide automatic failover of the NameNode? Choose 2 answers
A. ZKFailoverController
B. ZooKeeper
C. QuorumManager
D. JournalNode
Which HDFS command copies an HDFS file named foo to the local filesystem as localFoo?
A. hadoop fs -get foo LocalFoo
B. hadoop -cp foo LocalFoo
C. hadoop fs -Is foo
D. hadoop fs -put foo LocalFoo
A client application creates an HDFS file named foo.txt with a replication factor of 3. Identify which best describes the file access rules in HDFS if the file has a single block that is stored on data nodes A, B and C?
A. The file will be marked as corrupted if data node B fails during the creation of the file.
B. Each data node locks the local file to prohibit concurrent readers and writers of the file.
C. Each data node stores a copy of the file in the local file system with the same name as the HDFS file.
D. The file can be accessed if at least one of the data nodes storing the file is available.
For each intermediate key, each reducer task can emit:
A. As many final key-value pairs as desired. There are no restrictions on the types of those key-value pairs (i.e., they can be heterogeneous).
B. As many final key-value pairs as desired, but they must have the same type as the intermediate key-value pairs.
C. As many final key-value pairs as desired, as long as all the keys have the same type and all the values have the same type.
D. One final key-value pair per value associated with the key; no restrictions on the type.
E. One final key-value pair per key; no restrictions on the type.

Home | Contact Us | About Us | FAQ | Guarantee & Policy | Privacy & Policy | Terms & Conditions | How to buy
Copyright © 2025 pass4itsure.com. All Rights Reserved