DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST Online Practice Questions and Answers
Select the correct statement which applies to Principal component analysis (PCA):
A. Is a mathematical procedure that transforms a number of (possibly) correlated variables into a (smaller) number of uncorrelated variables.
B. Is a mathematical procedure that transforms a number of (possibly) correlated variables into a (higher) number of uncorrelated variables
C. Increase the dimensionality of the data set.
D. 1 and 3 are correct
E. 1 and 2 are correct
Which of the following steps you will be using in the discovery phase?
A. What all are the data sources for the project?
B. Analyze the Raw data and its format and structure.
C. What all tools are required, in the project?
D. What is the network capacity required
E. What Unix server capacity required?
A. It creates the smaller models
B. It requires the lesser memory to store the coefficients for the model
C. It reduces the non-significant features e.g. punctuations
D. Noisy features are removed


Let's say you have two cases as below for the movie ratings
1.
You recommend to a user a movie with four stars and he really doesn't like it and he'd rate it two stars
2.
You recommend a movie with three stars but the user loves it (he'd rate it five stars). So which statement correctly applies?
A. In both cases, the contribution to the RMSE is the same
B. In both cases, the contribution to the RMSE is the different
C. In both cases, the contribution to the RMSE, could varies
D. None of the above
You are working on a email spam filtering assignment, while working on this you find there is new word e.g. HadoopExam comes in email, and in your solutions you never come across this word before, hence probability of this words is coming in either email could be zero. So which of the following algorithm can help you to avoid zero probability?
A. Naive Bayes
B. Laplace Smoothing
C. Logistic Regression
D. All of the above
Logistic regression is a model used for prediction of the probability of occurrence of an event. It makes use of several variables that may be......
A. Numerical
B. Categorical
C. Both 1 and 2 are correct
D. None of the 1 and 2 are correct
You are using k-means clustering to classify heart patients for a hospital. You have chosen Patient Sex, Height, Weight, Age and Income as measures and have used 3 clusters. When you create a pair-wise plot of the clusters, you notice that there is significant overlap between the clusters. What should you do?
A. Identify additional measures to add to the analysis
B. Remove one of the measures
C. Decrease the number of clusters
D. Increase the number of clusters
Refer to the exhibit.
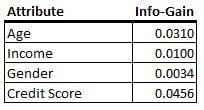
You are building a decision tree. In this exhibit, four variables are listed with their respective values of info-gain. Based on this information, on which attribute would you expect the next split to be in the decision tree?
A. Credit Score
B. Age
C. Income
D. Gender
Which of the following are advantages of the Support Vector machines?
A. Effective in high dimensional spaces.
B. it is memory efficient
C. possible to specify custom kernels
D. Effective in cases where number of dimensions is greater than the number of samples
E. Number of features is much greater than the number of samples, the method still give good performances
F. SVMs directly provide probability estimates

Home | Contact Us | About Us | FAQ | Guarantee & Policy | Privacy & Policy | Terms & Conditions | How to buy
Copyright © 2025 pass4itsure.com. All Rights Reserved